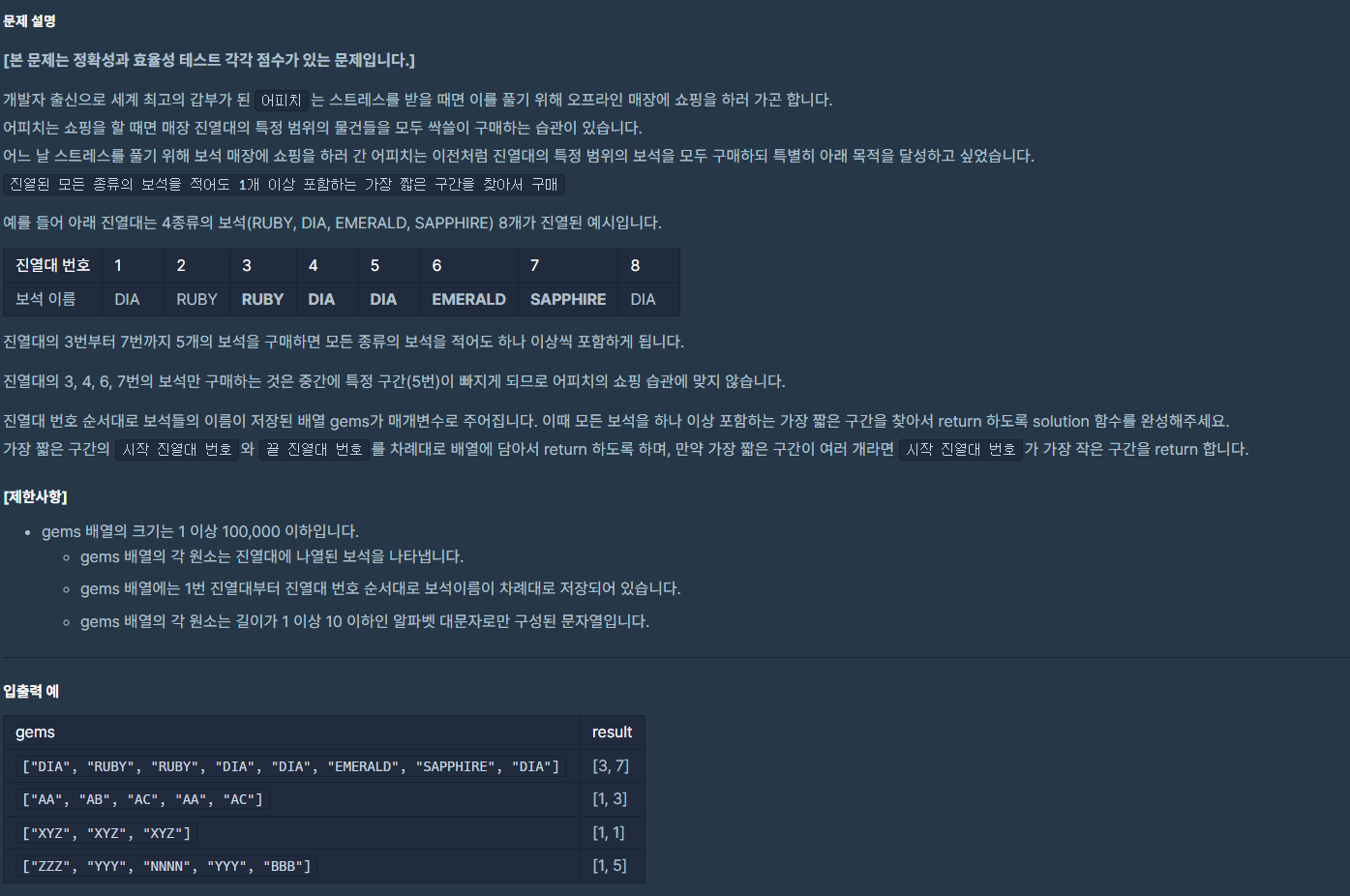
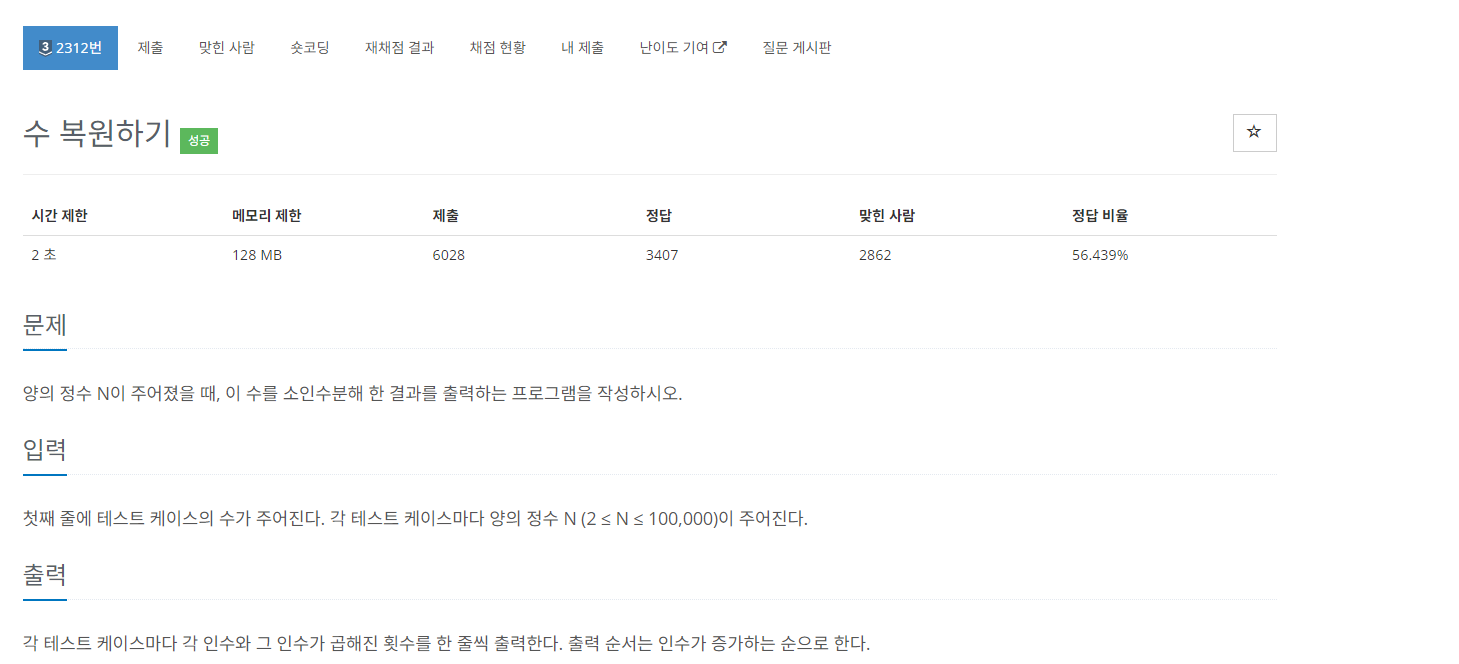
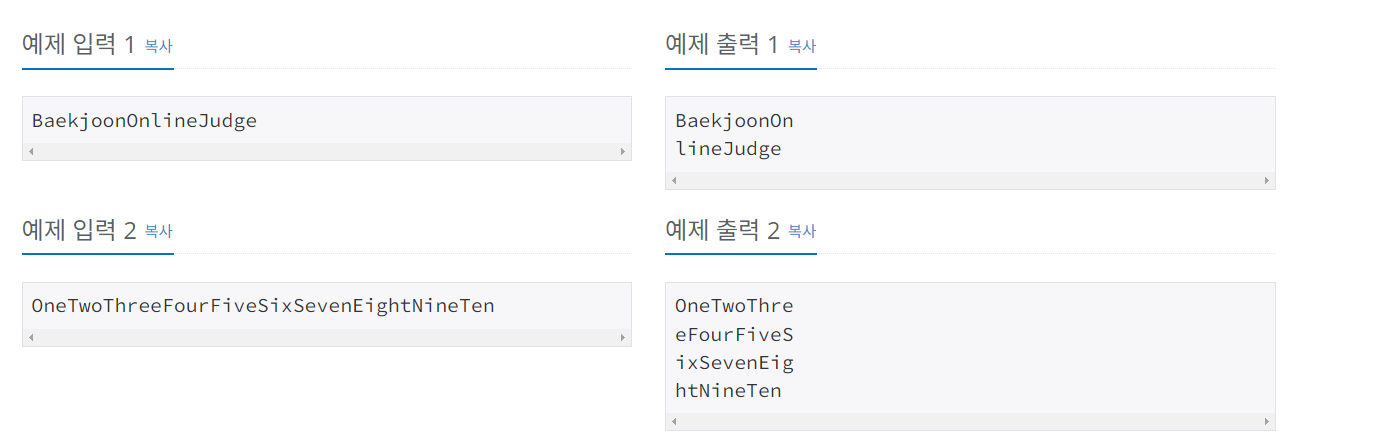
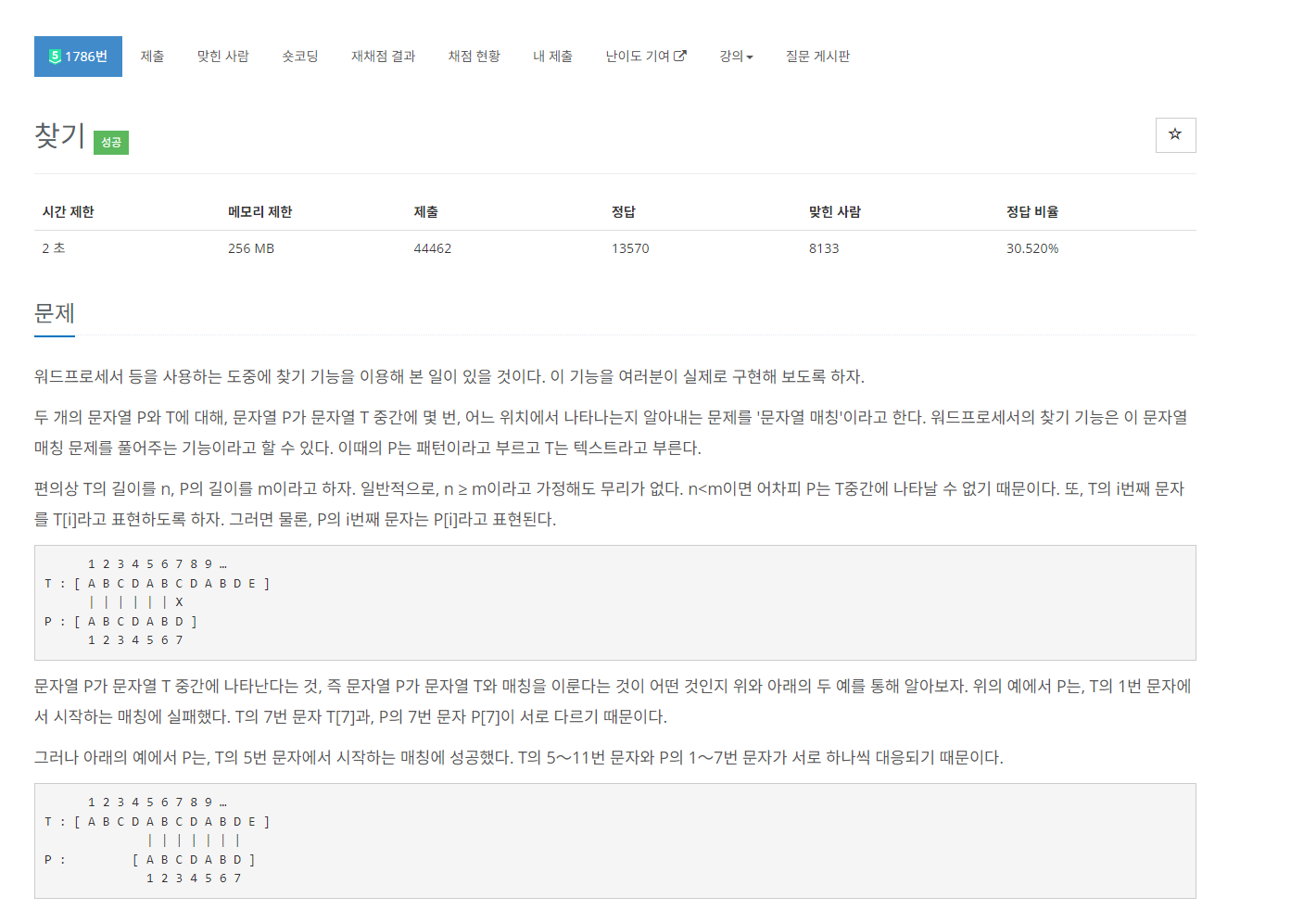
#우선 만냠이라는 어플리케이션은...
이 어플리케이션은
음식점 사이트 -냠톨릭에 이어서
같이 밥먹을 사람들 찾는 매칭 어플리케이션이다.
https://github.com/dfdfg42/CatholicTableMatching
GitHub - dfdfg42/CatholicTableMatching: 가톨릭대 혼밥 매칭 서비스
가톨릭대 혼밥 매칭 서비스. Contribute to dfdfg42/CatholicTableMatching development by creating an account on GitHub.
github.com
우선 어플리케이션이 어떻게 되어있는지 잠시 살펴보자면



이런식으로 매칭정보를 입력하고
매칭이 되면 문자로 수신 받을 수 있다.
#기존의 코드는..
우선 기존의 코드에 대해서 이해 할 필요가 있다.
그 전에 우선
각 유저는 원하는 시간 음식종류,이성인지 동성인지에 대한 매칭 폼을 작성한다
사용자의 matchform 은
음식종류,식사시간,성별
의 특성을 가지고 있다.
이걸 유저가 등록하면 유저와 동일한 matchform
을 가진 유저와 매칭을 해주는 것이다.
#그렇다면 기존의 코드는 어떻게 매칭되나..
우선 기존의 코드에 대해서 설명하자면
createMatch 함수로 1명 유저에 대해서 매칭을 시도한다
@Transactional
public Match createMatch(User user) {
lock.lock(); //락 함걸어봄
try {
MatchForm matchForm = user.getMatchForm();
List<User> potentialMatches = userRepository.findMatchesByPreferences(
matchForm.getFoodType(), matchForm.getTimeSlot(), matchForm.getPreferGender(), false);
for (User potentialMatch : potentialMatches) {
if (!potentialMatch.isMatched() && !potentialMatch.getId().equals(user.getId())
&& !potentialMatch.getGender().equals(user.getGender())) {
Match match = new Match(user, potentialMatch, new Date(), matchForm.getTimeSlot(), matchForm.getFoodType());
potentialMatch.setMatched(true);
user.setMatched(true);
userRepository.save(potentialMatch);
userRepository.save(user);
return matchRepository.save(match);
}
}
return null; // No match found
} finally {
lock.unlock(); // 락 임시
}
}
이 코드를 살펴보자면.
1.유저의 매치폼에 작성된 음식종류,시간,선호 성별과 동일한 매치폼을 가진 유저를 쿼리를 날려
리스트로 가져온다
2.리스트를 순회하며 아직 매칭이 안됬다면 매칭을 하고 갱신한다
이렇게 하나의 유저를 매칭하는데 전체 유저를 조회해야되서 n의 시간복잡도가 필요하다
#이후에 모든 유저에 대해서 매칭하기
createMatchForAllUsers 함수로 모든 유저에 대해서 matchCreate 함수를 실행하기
@Transactional
public void createMatchForAllUsers() {
List<User> users = userRepository.findAll();
List<Match> matches = new ArrayList<>();
for (User user : users) {
if(!user.isMatched() && !(user.getMatchForm()==null) ){
Match match = createMatch(user);
if (match != null) {
matches.add(match);
}
}
}
/* return matches; // 모든 매치 결과 반환*/
}
이렇게 매칭되지 않은 모든 유저에 대해서 createMatch를 해주면 매칭은 완료된다
모든유저(n) 에 대해서 createMatch(n)을 하였기 때문에 이말은 n^2 의 시간이 걸린다는소리다
#그럼 이제 개선을 해보자 (이진탐색트리) (n->logn)
우선 이진탐색 트리로 개선을 해보도록 하자.
foodType, timeSlot, preferGender 세 가지 특성 을 하나의 트리 노드에 넣도록 하자
treeNode 코드
public class TreeNode {
String foodType;
String timeSlot;
String preferGender;
List<User> users;
TreeNode left, right;
public TreeNode(String foodType, String timeSlot, String preferGender, User user) {
this.foodType = foodType;
this.timeSlot = timeSlot;
this.preferGender = preferGender;
this.users = new ArrayList<>();
this.users.add(user);
this.left = this.right = null;
}
}
트리 노드를 이용해서
이진 탐색 트리 코드를 작성하도록 하자
public class BinarySearchTree {
private TreeNode root;
public BinarySearchTree() {
this.root = null;
}
public void insert(String foodType, String timeSlot, String preferGender, User user) {
root = insertRec(root, foodType, timeSlot, preferGender, user);
}
private TreeNode insertRec(TreeNode root, String foodType, String timeSlot, String preferGender, User user) {
if (root == null) {
return new TreeNode(foodType, timeSlot, preferGender, user);
}
int cmp = compare(root, foodType, timeSlot, preferGender);
if (cmp > 0) {
root.left = insertRec(root.left, foodType, timeSlot, preferGender, user);
} else if (cmp < 0) {
root.right = insertRec(root.right, foodType, timeSlot, preferGender, user);
} else {
root.users.add(user);
}
return root;
}
public void remove(String foodType, String timeSlot, String preferGender, User user) {
root = removeRec(root, foodType, timeSlot, preferGender, user);
}
private TreeNode removeRec(TreeNode root, String foodType, String timeSlot, String preferGender, User user) {
if (root == null) return null;
int cmp = compare(root, foodType, timeSlot, preferGender);
if (cmp > 0) {
root.left = removeRec(root.left, foodType, timeSlot, preferGender, user);
} else if (cmp < 0) {
root.right = removeRec(root.right, foodType, timeSlot, preferGender, user);
} else {
Iterator<User> iterator = root.users.iterator();
while (iterator.hasNext()) {
User u = iterator.next();
if (u.equals(user)) {
iterator.remove();
break;
}
}
if (root.users.isEmpty()) {
if (root.left == null) return root.right;
if (root.right == null) return root.left;
TreeNode temp = findMin(root.right);
root.foodType = temp.foodType;
root.timeSlot = temp.timeSlot;
root.preferGender = temp.preferGender;
root.users = temp.users;
root.right = removeRec(root.right, temp.foodType, temp.timeSlot, temp.preferGender, user);
}
}
return root;
}
private TreeNode findMin(TreeNode root) {
while (root.left != null) root = root.left;
return root;
}
public List<User> search(String foodType, String timeSlot, String preferGender) {
return searchRec(root, foodType, timeSlot, preferGender);
}
private List<User> searchRec(TreeNode root, String foodType, String timeSlot, String preferGender) {
if (root == null) return new ArrayList<>();
int cmp = compare(root, foodType, timeSlot, preferGender);
if (cmp == 0) {
return root.users;
} else if (cmp > 0) {
return searchRec(root.left, foodType, timeSlot, preferGender);
} else {
return searchRec(root.right, foodType, timeSlot, preferGender);
}
}
private int compare(TreeNode node, String foodType, String timeSlot, String preferGender) {
int cmpFoodType = foodType.compareTo(node.foodType);
if (cmpFoodType != 0) return cmpFoodType;
int cmpTimeSlot = timeSlot.compareTo(node.timeSlot);
if (cmpTimeSlot != 0) return cmpTimeSlot;
return preferGender.compareTo(node.preferGender);
}
}
여기서 이진탐색의 비교 함수에 대해서 짚고 넘어가자면
각각의 문자열을 비교 해서 더 작은쪽이 왼쪽
큰 쪽이 오른쪽 으로 리턴을 하게 되어있다
문자열은 사전순으로 비교하게 된다
그림으로 이진 탐색 트리가 어떻게 구성되는지 그려보자
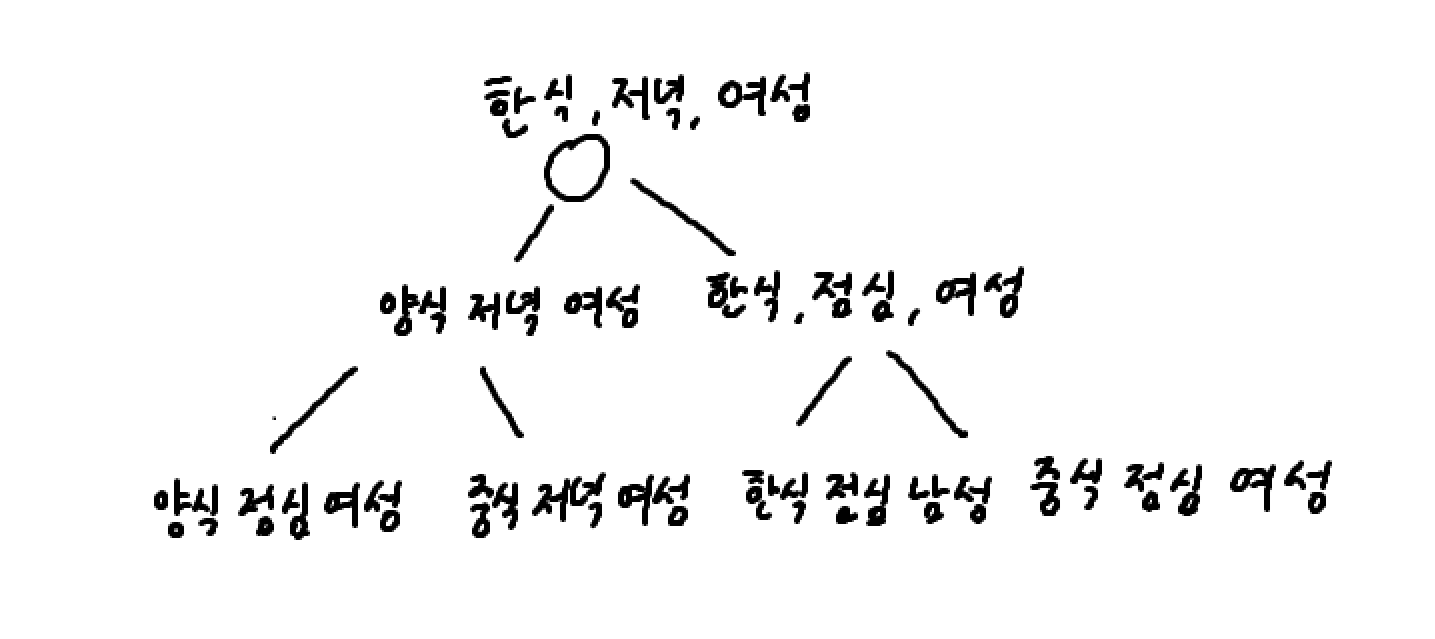
전부 다 그린건 아니지만 대략
이런식으로 이진탐색 트리가 구성되고
모든 특성에 대해서 이진 탐색 트리가 구성될 것이다.
이에 맞게 matchingService도 바꾸도록 하자
package com.csec.CatholicTableMatching.service;
import com.csec.CatholicTableMatching.BinarySearchTree;
import com.csec.CatholicTableMatching.domain.*;
import com.csec.CatholicTableMatching.repository.MatchFormRepository;
import com.csec.CatholicTableMatching.repository.MatchRepository;
import com.csec.CatholicTableMatching.security.domain.User;
import com.csec.CatholicTableMatching.security.repository.UserRepository;
import jakarta.transaction.Transactional;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
@Service
public class MatchingService {
private final BinarySearchTree binarySearchTree = new BinarySearchTree();
private final UserRepository userRepository;
private final MatchRepository matchRepository;
private final MatchFormRepository matchFormRepository;
// lock을 이용한 동시성 제어
private final Lock lock = new ReentrantLock();
public MatchingService(UserRepository userRepository, MatchRepository matchRepository, MatchFormRepository matchFormRepository) {
this.userRepository = userRepository;
this.matchRepository = matchRepository;
this.matchFormRepository = matchFormRepository;
initializeTreeWithUsers();
}
// 모든 유저를 트리에 삽입하는 메서드
private void initializeTreeWithUsers() {
List<User> users = userRepository.findAll();
for (User user : users) {
if (!user.isMatched() && user.getMatchForm() != null) {
addToIndex(user);
}
}
}
@Transactional
public void createMatchForAllUsers() {
List<User> users = userRepository.findAll();
List<Match> matches = new ArrayList<>();
for (User user : users) {
if (!user.isMatched() && user.getMatchForm() != null) {
addToIndex(user);
Match match = createMatch(user);
if (match != null) {
matches.add(match);
}
}
}
// return matches; // 모든 매치 결과 반환 (필요 시)
}
private void addToIndex(User user) {
MatchForm matchForm = user.getMatchForm();
binarySearchTree.insert(matchForm.getFoodType(), matchForm.getTimeSlot(), matchForm.getPreferGender(), user);
}
private void removeFromIndex(User user) {
MatchForm matchForm = user.getMatchForm();
binarySearchTree.remove(matchForm.getFoodType(), matchForm.getTimeSlot(), matchForm.getPreferGender(), user);
}
@Transactional
public Match createMatch(User user) {
lock.lock(); // 동시성 제어를 위한 lock
try {
MatchForm matchForm = user.getMatchForm();
List<User> potentialMatches = binarySearchTree.search(matchForm.getFoodType(), matchForm.getTimeSlot(), matchForm.getPreferGender());
for (User potentialMatch : potentialMatches) {
if (!potentialMatch.isMatched() && !potentialMatch.getId().equals(user.getId())
&& !potentialMatch.getGender().equals(user.getGender())) {
Match match = new Match(user, potentialMatch, new Date(), matchForm.getTimeSlot(), matchForm.getFoodType());
potentialMatch.setMatched(true);
user.setMatched(true);
removeFromIndex(user);
removeFromIndex(potentialMatch);
userRepository.save(potentialMatch);
userRepository.save(user);
return matchRepository.save(match);
}
}
return null; // No match found
} finally {
lock.unlock(); // 락 해제
}
}
@Transactional
public List<Match> MatchResult() {
return matchRepository.findAll();
}
@Transactional
public User findPartner(User user) {
User partner = matchRepository.findPartnerByUser1(user);
if (partner == null) {
partner = matchRepository.findPartnerByUser2(user);
}
return partner;
}
}
#이진탐색트리 개선 결과



매칭이 잘 되는걸 확인 할 수 있다.
#이진탐색 트리보다 해쉬맵이 낫지 않나? (logn->n)
분명 이진탐색트리로
각 특성을 가진 유저들을 log n 시간으로 조회할 수 있긴 하지만
이럴거면 그냥 해쉬맵을 사용하는게 더 좋지 않을까?
해쉬맵은 O(1)속도로 접근하는데
만약 유저가 전부 해쉬맵에 들어가있다면 비효율 적이겟지만
현 상황은 특성들만 분류하기때문에 굳이 이진탐색트리를 쓸 필요가 없다.
그러니 코드를 해쉬맵으로 바꾸자
각 특성별로 조합해 키를만들기만하면 된다.
그리고 추가적으로 umatched 유저들을 저장해두는 해쉬맵도 따로 만들도록 하자.
package com.csec.CatholicTableMatching.service;
import com.csec.CatholicTableMatching.BinarySearchTree;
import com.csec.CatholicTableMatching.domain.*;
import com.csec.CatholicTableMatching.repository.MatchFormRepository;
import com.csec.CatholicTableMatching.repository.MatchRepository;
import com.csec.CatholicTableMatching.security.domain.User;
import com.csec.CatholicTableMatching.security.repository.UserRepository;
import jakarta.transaction.Transactional;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
@Service
public class MatchingService {
private final HashMap<String, List<User>> userTable = new HashMap<>();
private final HashMap<String, List<User>> unmatchedUserTable = new HashMap<>();
private final UserRepository userRepository;
private final MatchRepository matchRepository;
private final MatchFormRepository matchFormRepository;
private final Lock lock = new ReentrantLock();
public MatchingService(UserRepository userRepository, MatchRepository matchRepository, MatchFormRepository matchFormRepository) {
this.userRepository = userRepository;
this.matchRepository = matchRepository;
this.matchFormRepository = matchFormRepository;
initializeTableWithUsers();
}
private void initializeTableWithUsers() {
List<User> users = userRepository.findAll();
for (User user : users) {
if (user.getMatchForm() != null) {
addToTable(user);
if (!user.isMatched()) {
addToUnmatchedTable(user);
}
}
}
}
@Transactional
public void createMatchForAllUsers() {
List<User> users = userRepository.findAll();
List<Match> matches = new ArrayList<>();
for (User user : users) {
if (!user.isMatched() && user.getMatchForm() != null) {
addToTable(user);
addToUnmatchedTable(user);
Match match = createMatch(user);
if (match != null) {
matches.add(match);
}
}
}
}
private void addToTable(User user) {
MatchForm matchForm = user.getMatchForm();
String key = generateKey(matchForm.getFoodType(), matchForm.getTimeSlot(), matchForm.getPreferGender());
userTable.computeIfAbsent(key, k -> new ArrayList<>()).add(user);
}
private void addToUnmatchedTable(User user) {
MatchForm matchForm = user.getMatchForm();
String key = generateKey(matchForm.getFoodType(), matchForm.getTimeSlot(), matchForm.getPreferGender());
unmatchedUserTable.computeIfAbsent(key, k -> new ArrayList<>()).add(user);
}
private void removeFromTable(User user) {
MatchForm matchForm = user.getMatchForm();
String key = generateKey(matchForm.getFoodType(), matchForm.getTimeSlot(), matchForm.getPreferGender());
List<User> users = userTable.get(key);
if (users != null) {
users.remove(user);
if (users.isEmpty()) {
userTable.remove(key);
}
}
}
private void removeFromUnmatchedTable(User user) {
MatchForm matchForm = user.getMatchForm();
String key = generateKey(matchForm.getFoodType(), matchForm.getTimeSlot(), matchForm.getPreferGender());
List<User> users = unmatchedUserTable.get(key);
if (users != null) {
users.remove(user);
if (users.isEmpty()) {
unmatchedUserTable.remove(key);
}
}
}
private String generateKey(String foodType, String timeSlot, String preferGender) {
return foodType + "|" + timeSlot + "|" + preferGender;
}
@Transactional
public Match createMatch(User user) {
lock.lock();
try {
MatchForm matchForm = user.getMatchForm();
String key = generateKey(matchForm.getFoodType(), matchForm.getTimeSlot(), matchForm.getPreferGender());
List<User> potentialMatches = unmatchedUserTable.getOrDefault(key, new ArrayList<>());
for (User potentialMatch : potentialMatches) {
if (!potentialMatch.isMatched() && !potentialMatch.getId().equals(user.getId())
&& !potentialMatch.getGender().equals(user.getGender())) {
Match match = new Match(user, potentialMatch, new Date(), matchForm.getTimeSlot(), matchForm.getFoodType());
potentialMatch.setMatched(true);
user.setMatched(true);
removeFromTable(user);
removeFromTable(potentialMatch);
removeFromUnmatchedTable(user);
removeFromUnmatchedTable(potentialMatch);
userRepository.save(potentialMatch);
userRepository.save(user);
return matchRepository.save(match);
}
}
return null;
} finally {
lock.unlock();
}
}
@Transactional
public List<Match> matchResult() {
return matchRepository.findAll();
}
@Transactional
public User findPartner(User user) {
User partner = matchRepository.findPartnerByUser1(user);
if (partner == null) {
partner = matchRepository.findPartnerByUser2(user);
}
return partner;
}
}
#결과
결과적으로 훨씬 빨라졌고
결과도 여전히 잘 나오는 것을 확인 할 수 있다.
O(n)에서 O(1)로 줄게 되었다.
모든 유저에 대해서 매칭을 하면 O(n)-> 에서 O(1)로 줄게 된 것이다.