백준 15811번 복면산?! [C++]
https://www.acmicpc.net/problem/15811
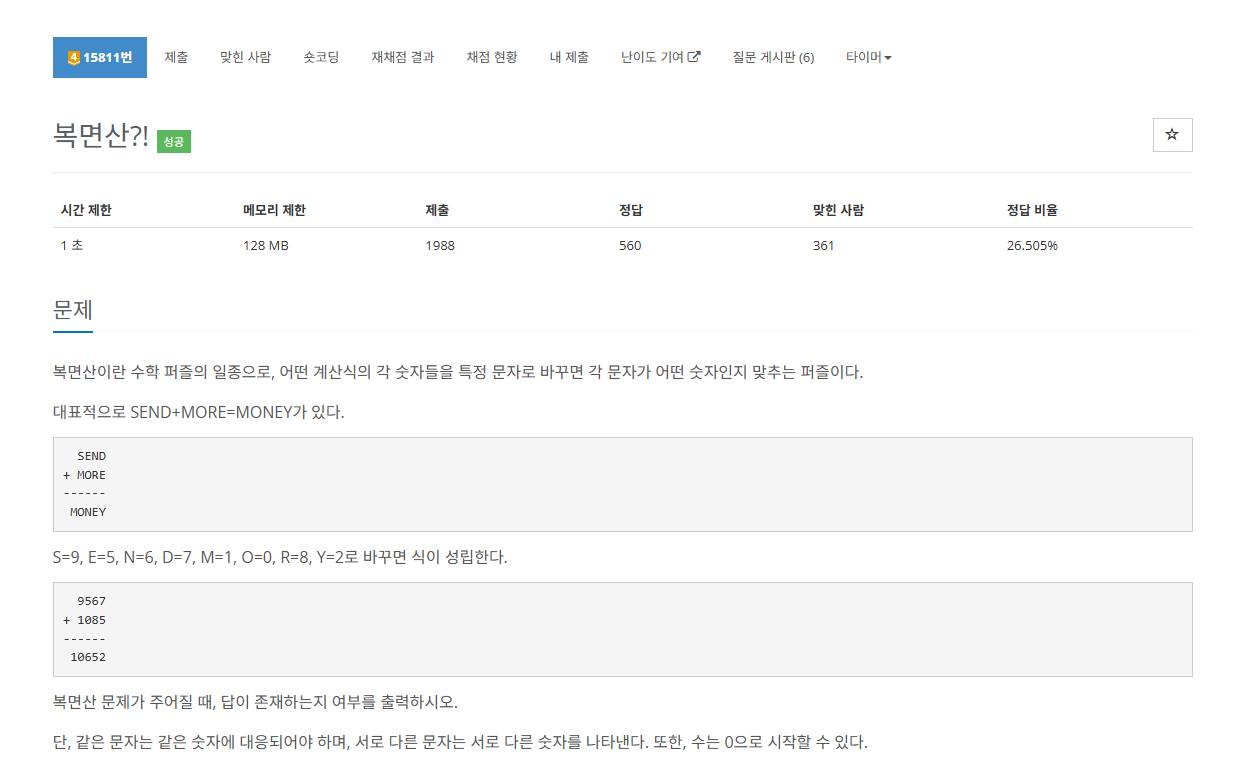
#문제 간단 정리
브루트포스 + 백트래킹 문제
다만 최적화가 좀 필요하다
#문제 해결 방법
우선 제일 주목해야 될점은
숫자는 0~9까지밖에 없으니까
한번에 나오는 알파벳은 10개로 제한된다.
즉 알파벳을 할당하는데 10!이라서 충분히 가능해 보인다.
거기에 18길이의 단어니까 18*3 * 10! 해도 충분해 보이니
#include <iostream>
#include <unordered_map>
#include <string>
#include <sstream>
#include <vector>
#include <map>
using namespace std;
unordered_map<char, int> mapping;
vector<pair<char, int>> alphas;
vector<string> token;
bool possible;
bool used[10] = { false };
void check() {
int a = 0, b = 0, c = 0;
int cnt = 1;
for (int i = token[0].size() - 1; i >= 0; i--) {
a += cnt * mapping[token[0][i]];
cnt *= 10;
}
cnt = 1;
for (int i = token[1].size() - 1; i >= 0; i--) {
b += cnt * mapping[token[1][i]];
cnt *= 10;
}
cnt = 1;
for (int i = token[2].size() - 1; i >= 0; i--) {
c += cnt * mapping[token[2][i]];
cnt *= 10;
}
if (a + b == c) {
possible = true;
}
}
void dfs(int idx) {
if (possible) return;
if (idx == alphas.size()) {
check();
return;
}
for (int i = 0; i <= 9; i++) {
if (used[i]) continue;
used[i] = true;
alphas[idx].second = i;
mapping[alphas[idx].first] = i;
dfs(idx + 1);
used[i] = false;
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
string word1, word2, word3;
cin >> word1 >> word2 >> word3;
token.push_back(word1);
token.push_back(word2);
token.push_back(word3);
for (auto &word : token) {
for (char ch : word) {
if (mapping.find(ch) == mapping.end()) {
mapping[ch] = -1;
alphas.push_back({ ch, -1 });
}
}
}
possible = false;
dfs(0);
cout << (possible ? "YES" : "NO") << "\n";
return 0;
}
이렇게 풀었더니 틀렸다.
문제점은 unordered map 을 사용했기 때문에
알파벳에 할당된 숫자를 조회하는데 오버헤드가 크기 때문이였다.
unordered_map은 해시 함수 계산, 버킷 관리, 메모리 할당 등 내부적으로 복잡한 처리가 있어서 키의 개수가 적은 경우에도 오버헤드가 상대적으로 크게 작용하게 된다.
map은 균형 이진 탐색 트리(RB 트리 등)로 구현되어 있는데, 키의 개수가 매우 적으면 log n 이라서
키가 적은 경우에는 거의 상수와 같다.
때문에 언오더 맵이 더 빠를거란 생각과 다르게 map 을사용해주면된다.
생각보다 언오더 맵때문에 시간초과가 나는일이 빈번하다.
#include <iostream>
#include <unordered_map>
#include <string>
#include <vector>
#include <map>
#include <cmath>
using namespace std;
unordered_map<char, int> mapping;
vector<pair<char, int>> alphas;
vector<string> token;
unordered_map<char, long long> coef;
bool possible;
bool used[10] = { false };
void precomputeCoef() {
// token[0]와 token[1]는 양의 가중치, token[2]는 음의 가중치
// 자리수는 가장 왼쪽이 최고 자리이므로, weight = 10^(len - i - 1)
for (int t = 0; t < 3; t++) {
int len = token[t].size();
int sign = (t < 2) ? 1 : -1; // token0, token1: +1, token2: -1
for (int i = 0; i < len; i++) {
char ch = token[t][i];
long long weight = 1;
for (int j = 0; j < len - i - 1; j++) {
weight *= 10;
}
coef[ch] += sign * weight;
}
}
}
void check() {
long long total = 0;
// 모든 등장 문자에 대해 mapping값과 미리 구한 계수를 곱해 더함
for (auto& p : mapping) {
total += (long long)p.second * coef[p.first];
}
if (total == 0)
possible = true;
}
void dfs(int idx) {
if (possible) return;
if (idx == alphas.size()) {
check();
return;
}
for (int i = 0; i <= 9; i++) {
if (used[i]) continue;
used[i] = true;
alphas[idx].second = i;
mapping[alphas[idx].first] = i;
dfs(idx + 1);
used[i] = false;
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
string word1, word2, word3;
cin >> word1 >> word2 >> word3;
token.push_back(word1);
token.push_back(word2);
token.push_back(word3);
// 등장하는 문자들만 mapping 및 alphas에 저장
for (auto& word : token) {
for (char ch : word) {
if (mapping.find(ch) == mapping.end()) {
mapping[ch] = -1;
alphas.push_back({ ch, -1 });
}
}
}
precomputeCoef();
possible = false;
dfs(0);
cout << (possible ? "YES" : "NO") << "\n";
return 0;
}
이렇게 map 을 사용하면 맞는다

그리고 결국
숫자를 할당하는 부분에서 시간초과가 난것이라
상수시간에 해결할 수 있는 방법이 있는데
각 숫자의 자리수를 기억하는것이다
예를들어 MONEY + MOM = HOME
인 경우에는
M 은 첫번째단어에 5자리숫자니까 10000
두번째 단어에 3자리 1자리 숫자니까 100 + 1
이렇게 수식 왼쪽 부분 은 10101 이고 좌측 부분은
음수로 계산해서 -10 이된다
이렇게 가중치를 더해놔서 10101 - 10 = 10091
M은 가중치 10091 으로 여기에 M이 할당된 숫자를 곱해서
다른 알파벳들도 다 같이 가중치를 곱해서 더해줫을때
결국 0이되면 정답인 것이라
가중치를 미리 구해놓는방법도 가능하다 .
다시설명하자면
우리가 수를 읽을 때, 각 자리수는 1, 10, 100, 1000 등 10의 거듭제곱으로 표현
- 예를 들어, 9567은
9×1000+5×100+6×10+
이런 식입니다. - 문제에서의 역할
예를 들어, SEND+MORE=MONEY 같은 문제에서,- S는 1000자리,
- E는 100자리,
- N은 10자리,
- D는 1자리 등
각 문자가 자리수에 따라 곱해지는 값(가중치)가 다릅니다.
- 전처리 (Preprocessing)로 미리 계산
- token[0]와 token[1] (즉, 덧셈하는 두 수):
각 문자가 나타나는 자리수에 맞춰 + 가중치 - token[2] (결과 값):
각 문자가 나타나는 자리수에 맞춰 - 가중치
- S에 1000, E에 100, N에 10, D에 1의 가중치
“a + b == c” 를 확인할 때,
각 문자에 할당된 숫자에 이 가중치를 곱한 값을 모두 더한 결과가 0이 되어야 한다 - token[0]와 token[1] (즉, 덧셈하는 두 수):
그렇게 풀게되면
#include <iostream>
#include <unordered_map>
#include <string>
#include <vector>
#include <map>
#include <cmath>
using namespace std;
unordered_map<char, int> mapping;
vector<pair<char, int>> alphas;
vector<string> token;
unordered_map<char, long long> coef;
bool possible;
bool used[10] = { false };
void precomputeCoef() {
// token[0]와 token[1]는 양의 가중치, token[2]는 음의 가중치
// 자리수는 가장 왼쪽이 최고 자리이므로, weight = 10^(len - i - 1)
for (int t = 0; t < 3; t++) {
int len = token[t].size();
int sign = (t < 2) ? 1 : -1; // token0, token1: +1, token2: -1
for (int i = 0; i < len; i++) {
char ch = token[t][i];
long long weight = 1;
for (int j = 0; j < len - i - 1; j++) {
weight *= 10;
}
coef[ch] += sign * weight;
}
}
}
void check() {
long long total = 0;
// 모든 등장 문자에 대해 mapping값과 미리 구한 계수를 곱해 더함
for (auto& p : mapping) {
total += (long long)p.second * coef[p.first];
}
if (total == 0)
possible = true;
}
void dfs(int idx) {
if (possible) return;
if (idx == alphas.size()) {
check();
return;
}
for (int i = 0; i <= 9; i++) {
if (used[i]) continue;
used[i] = true;
alphas[idx].second = i;
mapping[alphas[idx].first] = i;
dfs(idx + 1);
used[i] = false;
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
string word1, word2, word3;
cin >> word1 >> word2 >> word3;
token.push_back(word1);
token.push_back(word2);
token.push_back(word3);
// 등장하는 문자들만 mapping 및 alphas에 저장
for (auto& word : token) {
for (char ch : word) {
if (mapping.find(ch) == mapping.end()) {
mapping[ch] = -1;
alphas.push_back({ ch, -1 });
}
}
}
precomputeCoef();
possible = false;
dfs(0);
cout << (possible ? "YES" : "NO") << "\n";
return 0;
}
이런 코드가 된다.